
A cloud native application may use several backing services, for things like messaging and data management. Typically these backing services are deployed separately from the application services, so multiple application instances (environments) can utilize them. Also, these backing services typically run as a cluster. In this blog post, I will show you how you can use Docker and Nirmata to easily deploy and operate a production Zookeeper cluster.
Nirmata has been designed and built from the ground up to deploy and operate Microservices applications, packaged in application containers. However Beyond basic orchestration, Nirmata’s sophisticated policy-based orchestration and lifecycle management features can also orchestrate can also deploy and operate cluster services such as Zookeeper, Kafka, MongoDB, etc.
Cluster services require a different level of orchestration compared to "regular" Microservices. They tend to be more complex to configure, and typically have configuration dependencies,less elastic in nature than true Microservices. For instance, adding or removing a node may requires a restart the other nodes in order to sync-up their configuration. The setup often involves specifying the IP address and ports of the other nodes in a configuration. It means that the placement of all the nodes must be calculated first before the configuration files of a the nodes can be derived.
It is important to realize that not all cluster services behave in the same way. For instance, a MongoDB cluster is more elastic than a Zookeeper cluster. Adding nodes to Zookeeper requires restarting the other node. MongoDB doesn't require that.
Deploying Zookeeper
With Nirmata you can deploy a Zookeeper cluster in three easy steps:
- Create a public or private Cloud Provider, and Host Group with 3 hosts
- Import the Zookeeper blueprint
- Deploy the Zookeeper cluster in an Environment
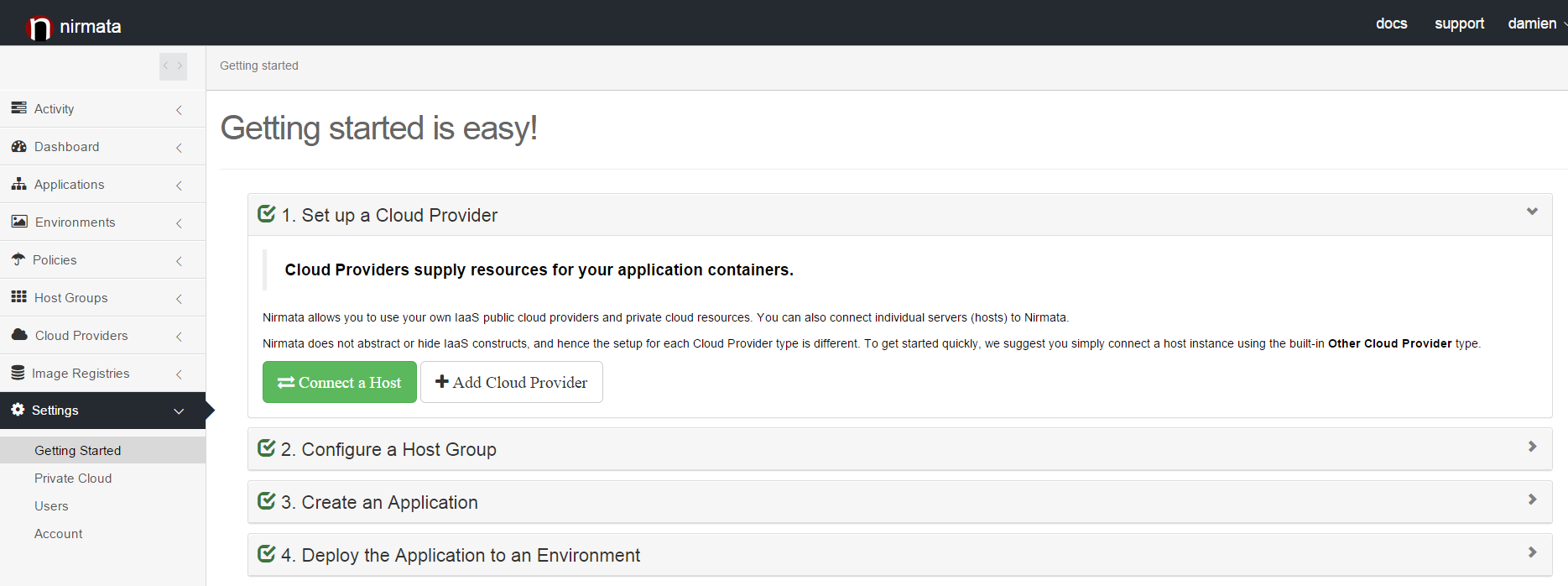
Step 1 : Creating a Cloud Provider and a Host Group
You must first go through the initial setup to on-board the cloud resources you want the use to deploy your Zookeeper cluster. You can either deploy your cluster in one of the public clouds we support or even in your private cloud on Openstack or VSphere.
Step 2 : Importing the Zookeeper Blueprint
Next, you can import the Nirmata Zookeeper blueprint into your account. Using the navigation panel, go to the Applications panel and import the Zookeeper blueprint.
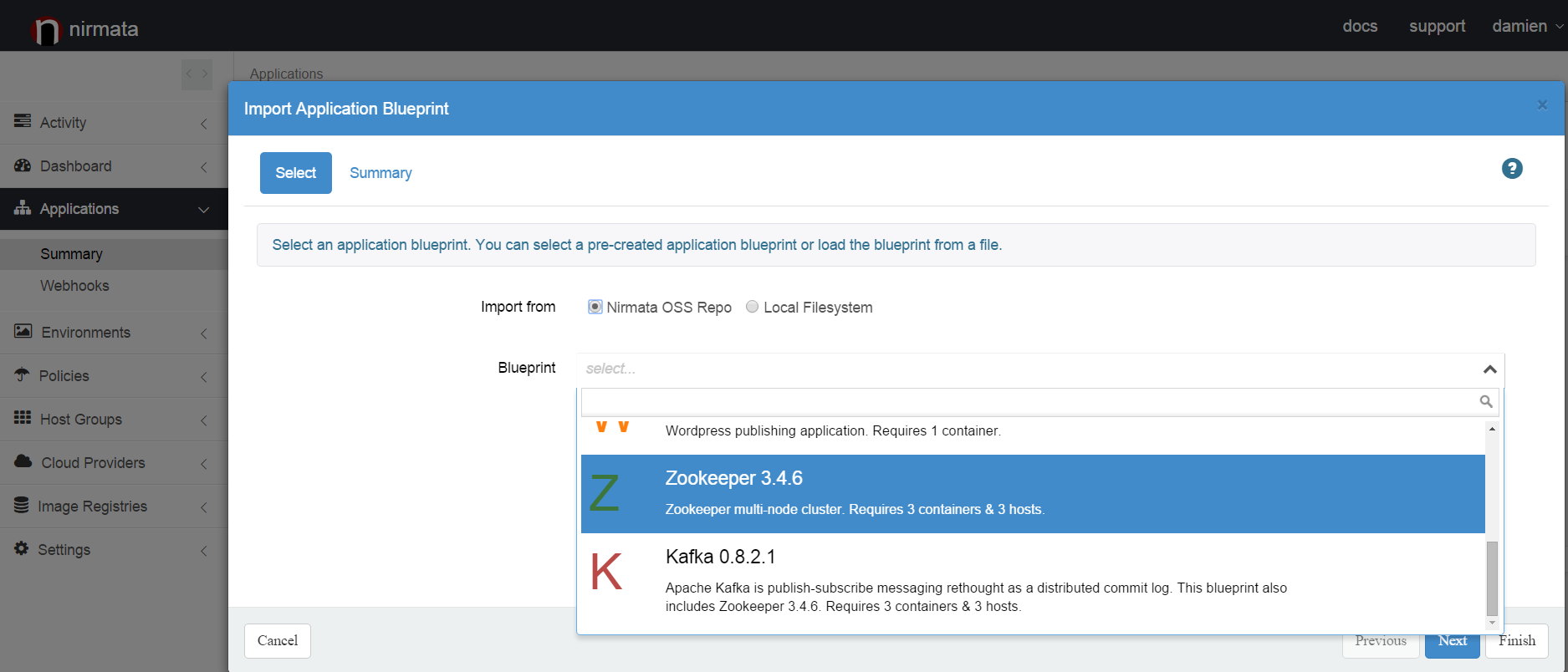
You can expand the application definition to see the details of the blueprint. The details of the blueprint will be explained in the last part of this post.
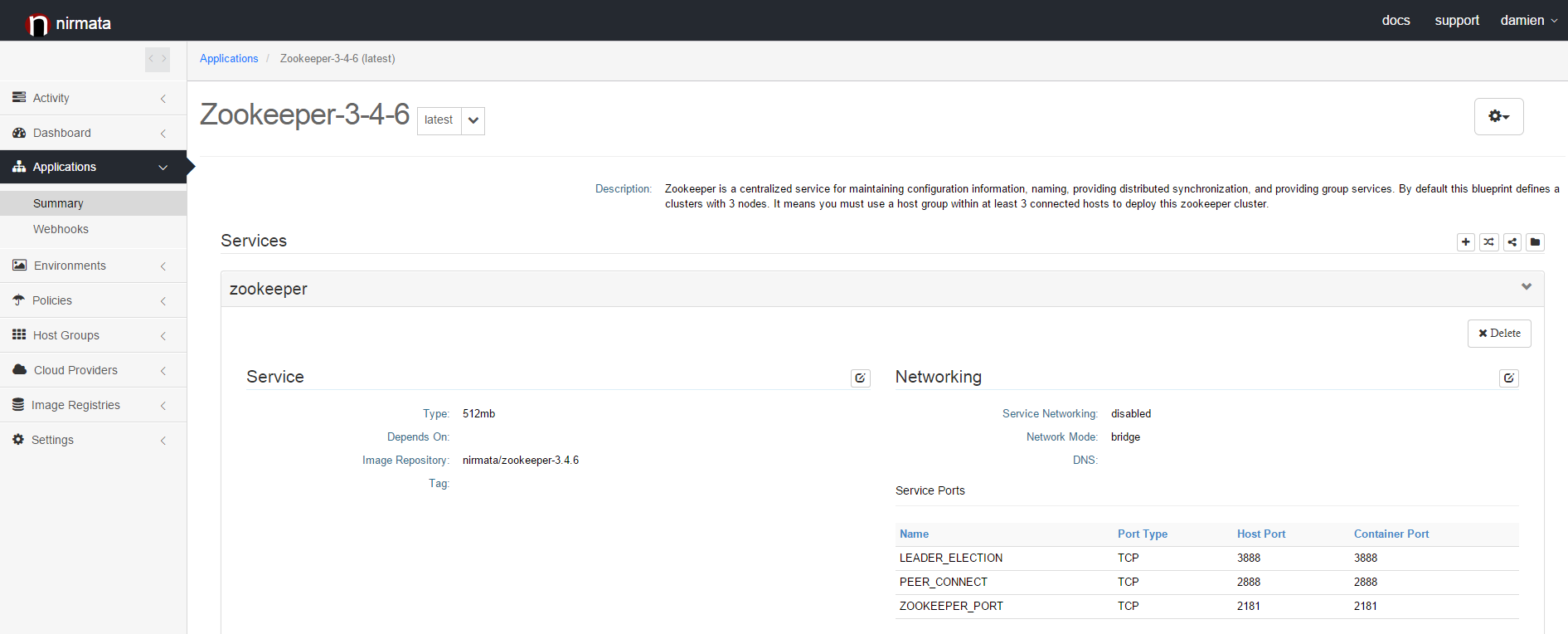
A blueprint is only a logical definition of an application. At this point, the Zookeeper cluster is not running in your cloud. The next step consists of deploying the cluster in an Environment. An environment is a runtime instantiation of an application.
Step 3 : Creating an Environment
To deploy the cluster, use the navigation panel on the left and select "Environments". Click on the Add button.
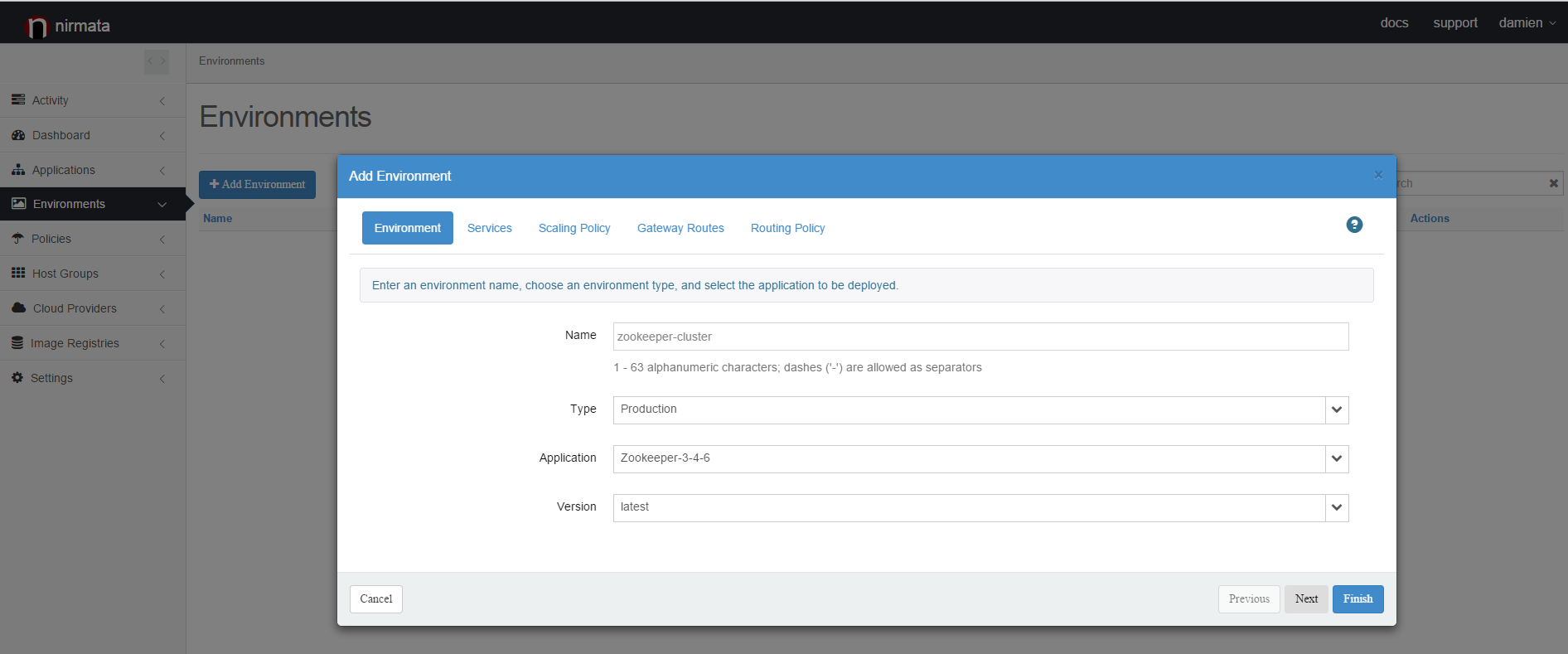
The only mandatory parameters you need to specify are the name of your environment, the type of the environment (Production, Staging or Sandbox) and the application blueprint you want to deploy, Zookeeper-3.4.6 in this case. Now, just click the Finish button to trigger the deployment. At this point, Nirmata will compute the placement of the 3 Zookeeper containers required for this cluster. Then it will create the containers on the hosts you configured in your Host Group. When the container creation and the health check is completed you will see the 3 Zookeeper nodes in a running state.
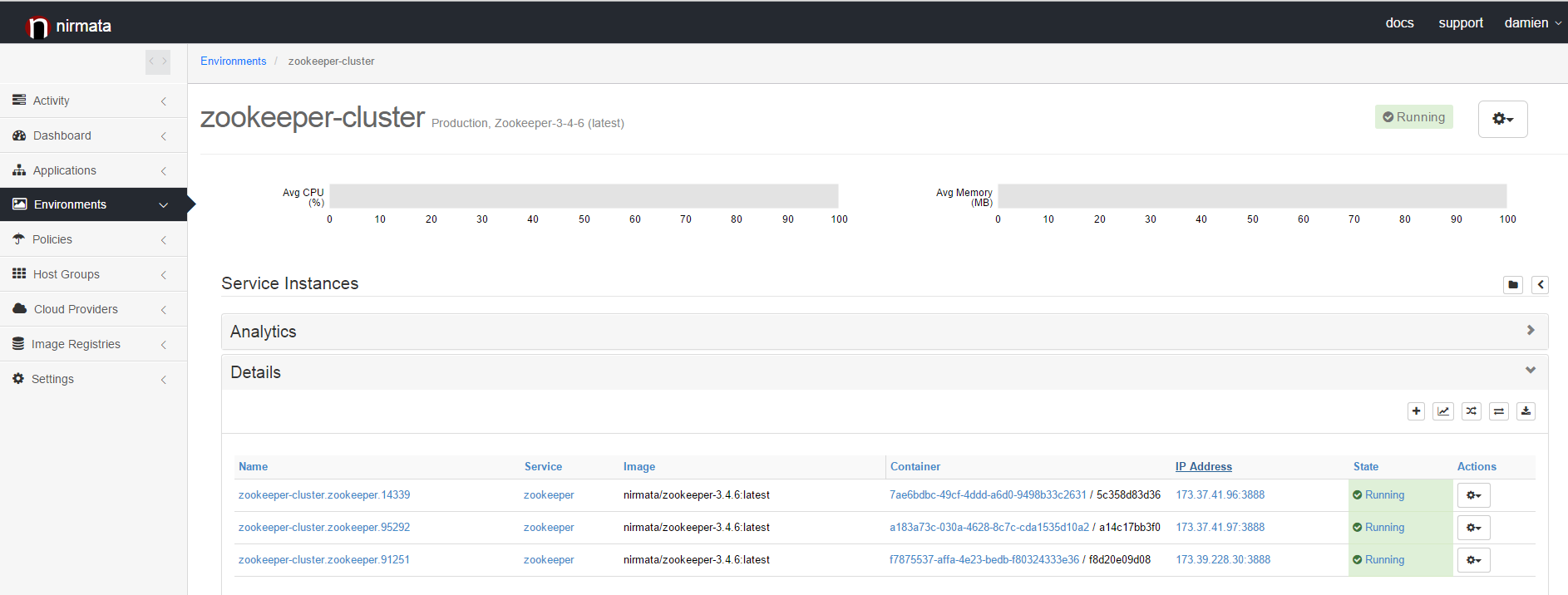
And that is it, your Zookeeper cluster is ready!
Operating a Zookeeper Cluster
We have just seen that deploying a zookeeper at scale on public cloud or private cloud can be done very quickly using Nirmata. We will now see how you can operate and maintain your cluster. We will cover 5 typical use cases:
- Verifying the state of your cluster
- Changing the configuration parameters of the Zookeeper nodes
- Scaling up the Zookeeper cluster
- Scaling down the Zookeeper cluster
- Zookeeper nodes resiliency
Inspecting the State of your Cluster
You can first look at the logs produced by each node. Base on the Zookeeper blueprint definition logs are located under /mnt/zookeeper:
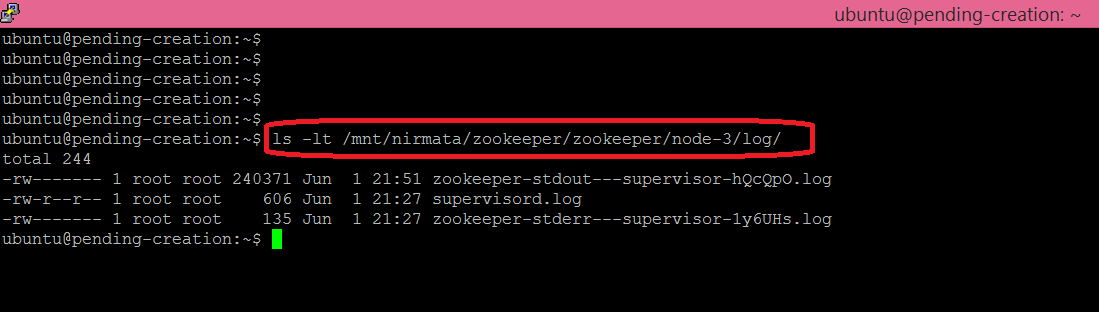
Next you can list the Docker container, enter into the container using the Docker exec command :

Then you can inspect the configuration that was generated to start this node. You should see that the 3 nodes are specified in the configuration file:
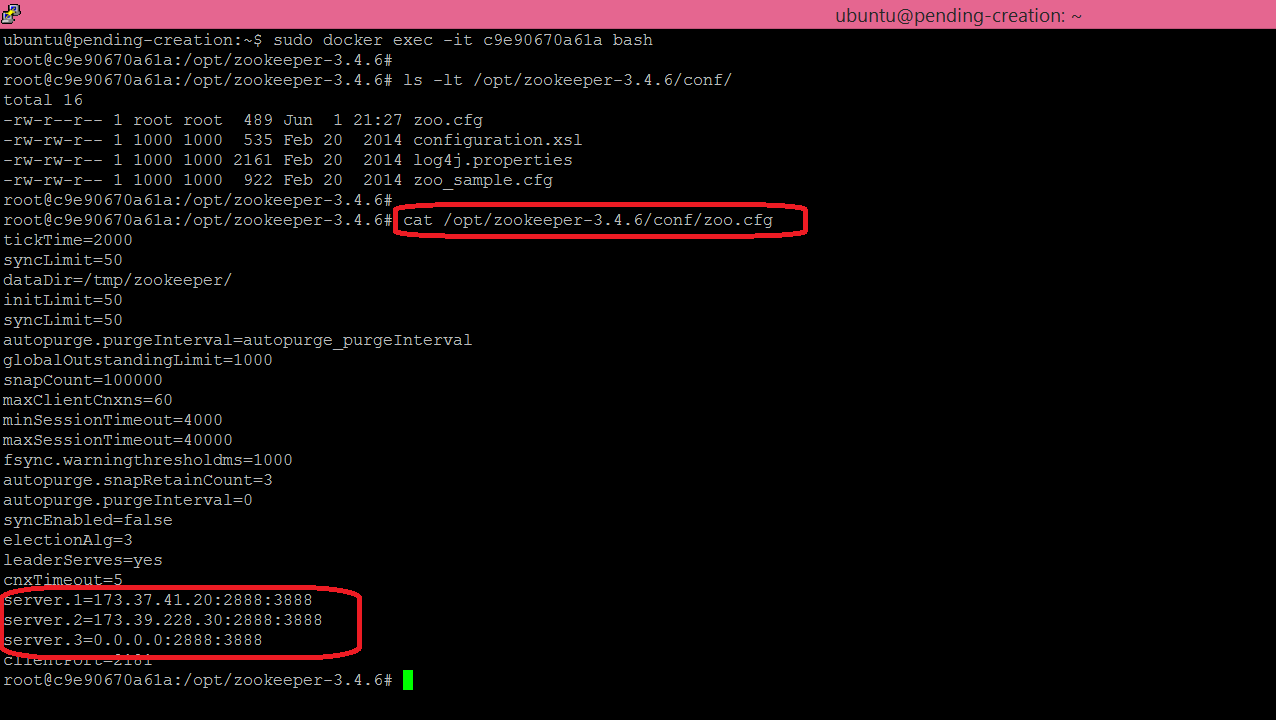
You can also verify the role of each node by using the Zookeeper 4 letters administrative commands. You should see that one node is the leader and two nodes are followers:
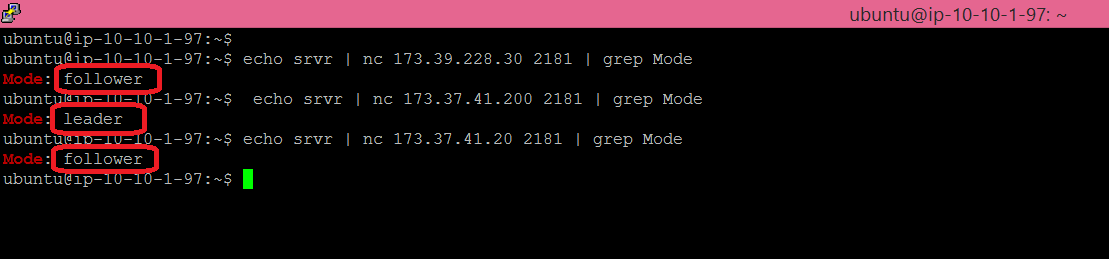
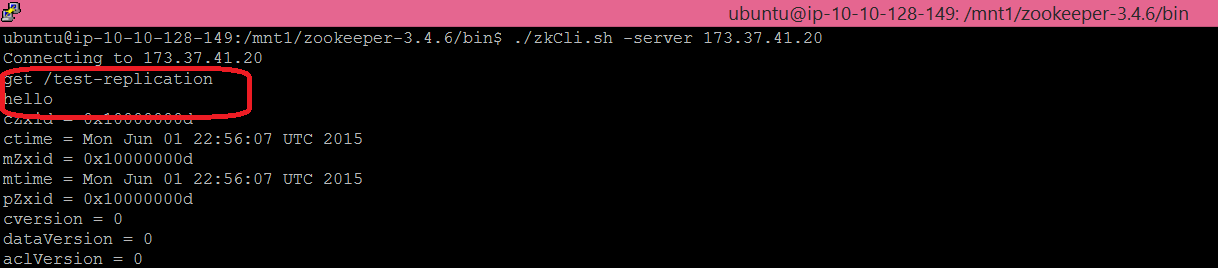
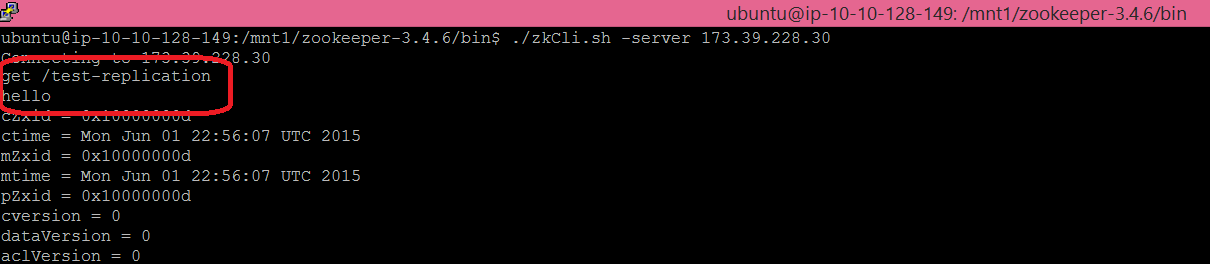
Finally, using the Zookeeper CLI, you can verify that the data replication is happening across all nodes. Connect to your leader member then create some data. Then connect to the other two members of the cluster and verify that the same data is visible.

Changing Zookeeper Parameters
We have exposed some of the Zookeeper parameters in the Zookeeper blueprint. You can change a parameter value by editing the blueprint and then restarting the nodes. To edit the blueprint, go to the navigation panel and then select "Applications". Click on the Zookeeper-3.4.6 blueprint and then expand the zookeeper service definition. Click on the Edit button of the Run Settings section. You can now modify the parameter value of your choice.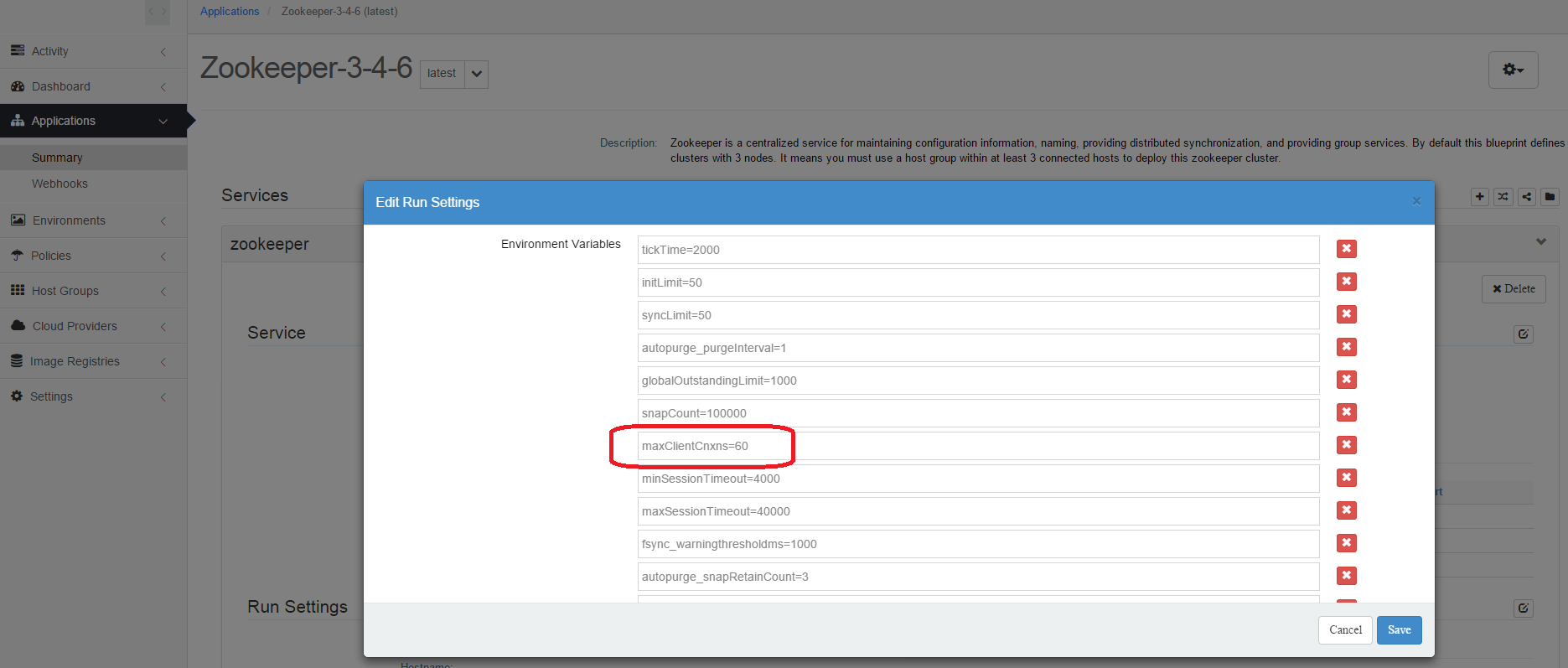
For this change to take effect, you must now restart the Zookeeper nodes one after another. Go to the environment you have created and right-click on the first node that you to restart. Then select the "Restart" option.
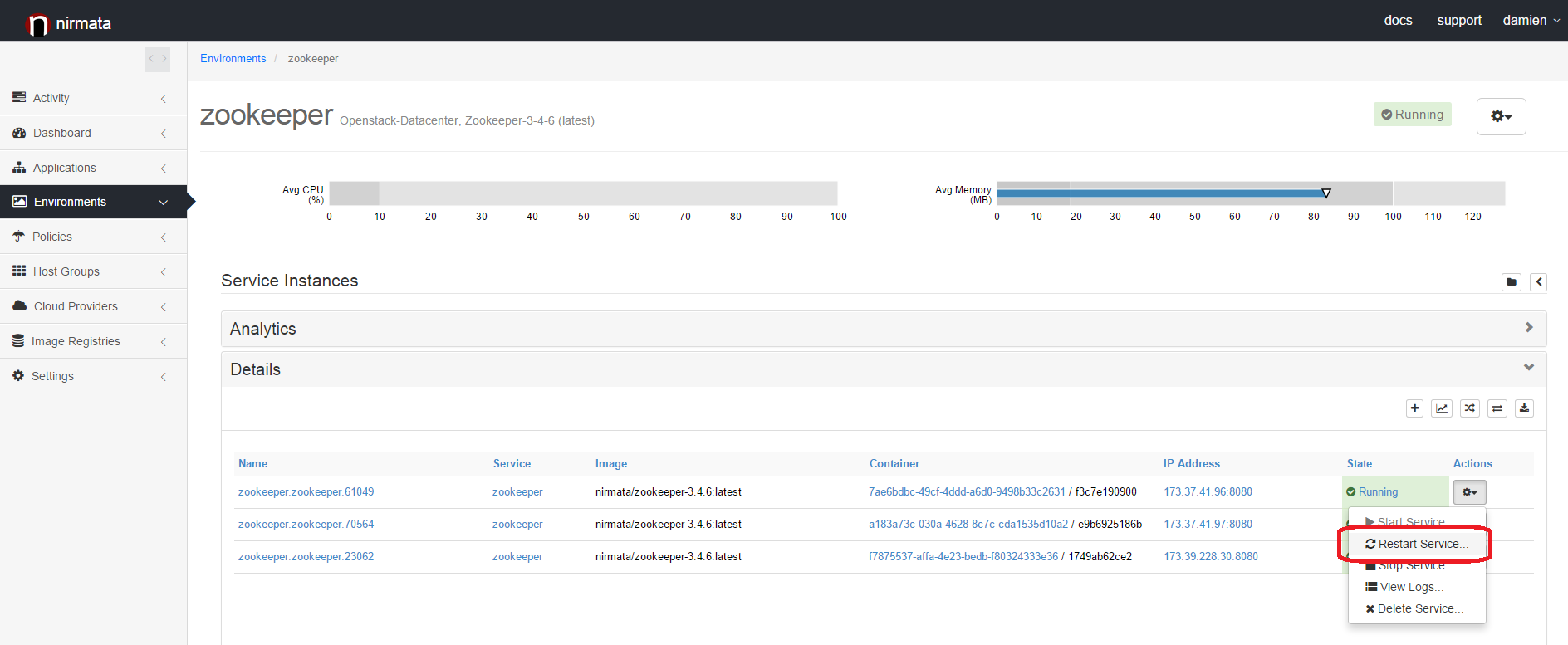
Now, you can restart the remaining nodes.
Scaling-Up the Cluster
To scale up your cluster, you can edit the scaling rules in your environment. Before actually creating new nodes, make use your host group has enough hosts. In our case, we are going to scale the cluster from 3 nodes to 5, so our host group has 5 hosts.
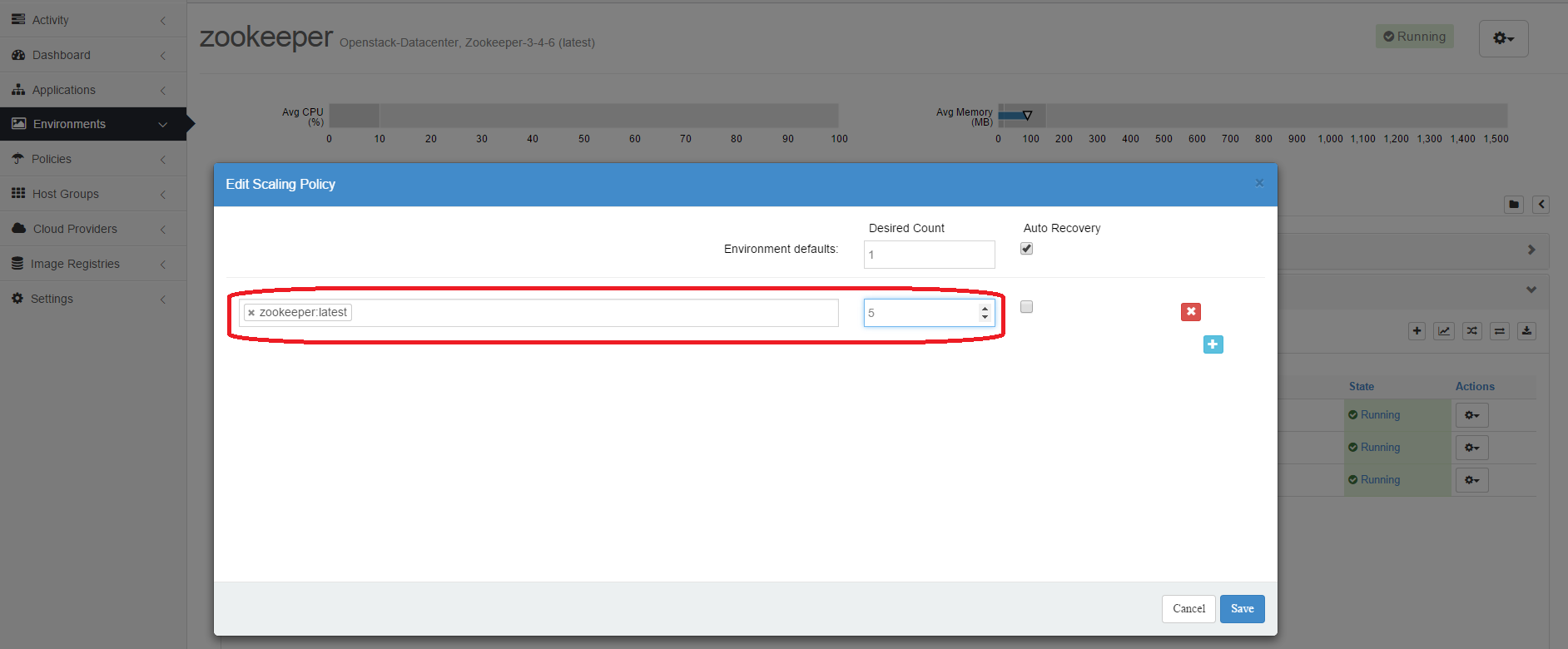
Once the additional 2 nodes are in running state you can restart the 3 other nodes to make sure all 5 nodes have the same configuration.
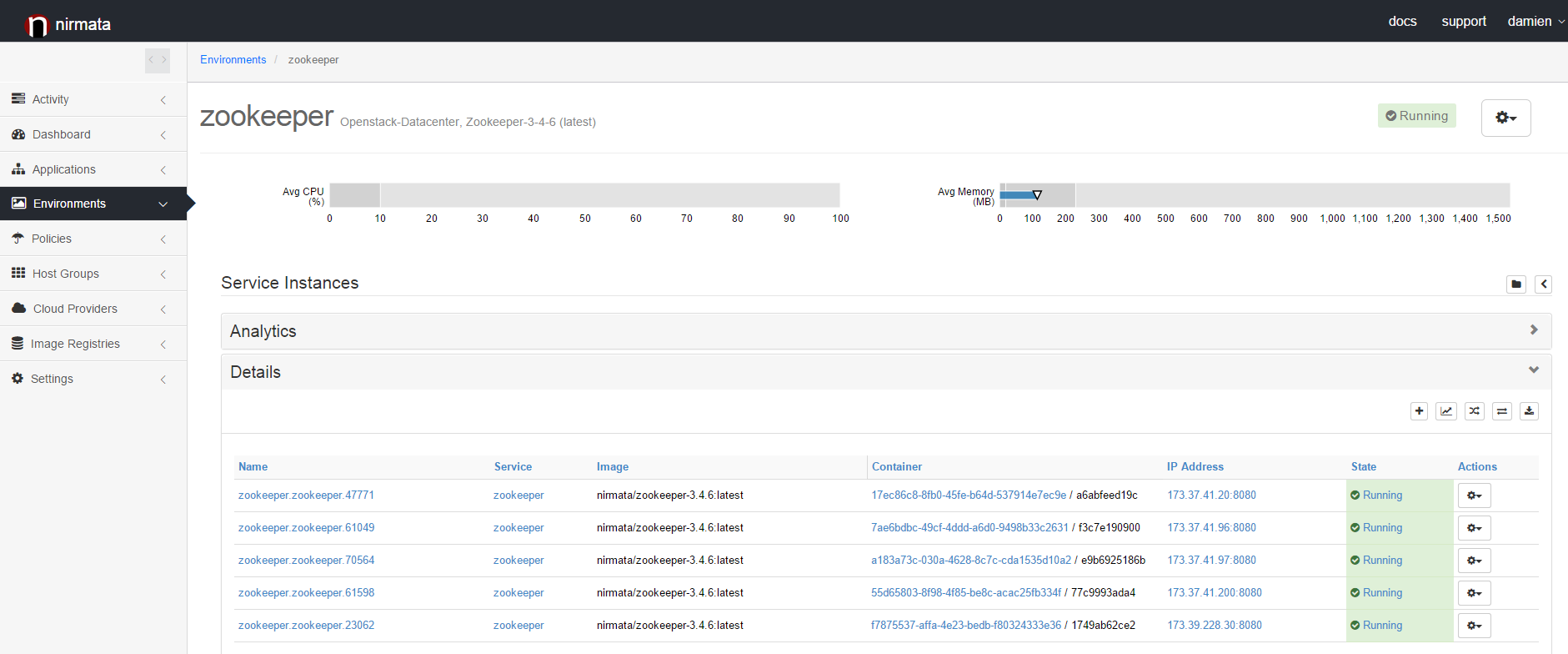
Scaling-Down the Cluster
The process of scaling down your cluster is very similar to the one used to scale up. If you want to scale down from 5 nodes to 3, edit the scaling policy in your environment and set the desired count to 3. Nirmata orchestration will shut down two out of the five running nodes. Then you can restart the 3 remaining nodes to make sure their configuration is up-to-date
You can also be specific regarding which of the two nodes you want to shut down. Instead of editing the scaling rule, delete directly the instance you want to remove from the cluster. Make sure to select the option "Decrements scaling rule".
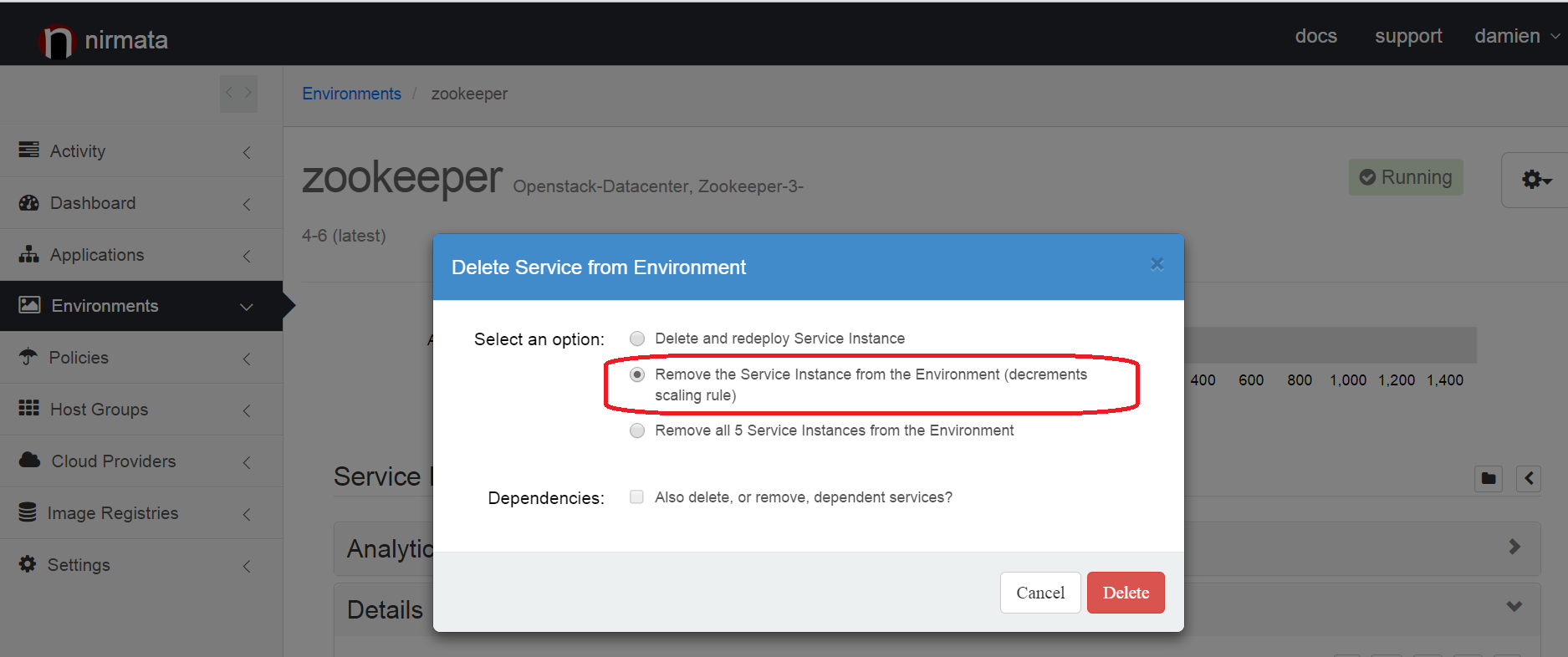
Zookeeper Nodes Resiliency
Nirmata provides out-of-the-box service instance resiliency. If a service instance is deleted or if a container fails then Nirmata will restart your service instance automatically. For regular Microservices, the service instance can be restarted on the same host or on a different host depending on the memory and ports available on each host at that time. With cluster services such as Zookeeper, Nirmata will always try to restart the service instance on the same host. This is done to guaranty that the configuration of the other nodes and the configuration of the Zookeeper clients are still valid after the node has recovered.
Zookeeper Cluster Clients
Now that your cluster is up and running, you probably want to connect your application to it. If your application is not deployed using Nirmata, you need to provide the Zookeeper connect string to your application. To format the connect string, you can look at the IP address of the hosts where the nodes are running. You will also need to know the Zookeeper client port. This port is specified in the blueprint with a value of 2181.
Another option is to deploy your application using Nirmata in the same environment where the Zookeeper cluster is running. You can execute the following steps to to this:
- Import the Zookeeper blueprint and use it a starting point for your own blueprint (rename it to the name of your application).
- Add the definition of your services to this blueprint.
- Deploy your application blueprint in an environment
When adding the definition of your services to the blueprint, make sure to specify that your services depends on the Zookeeper service:
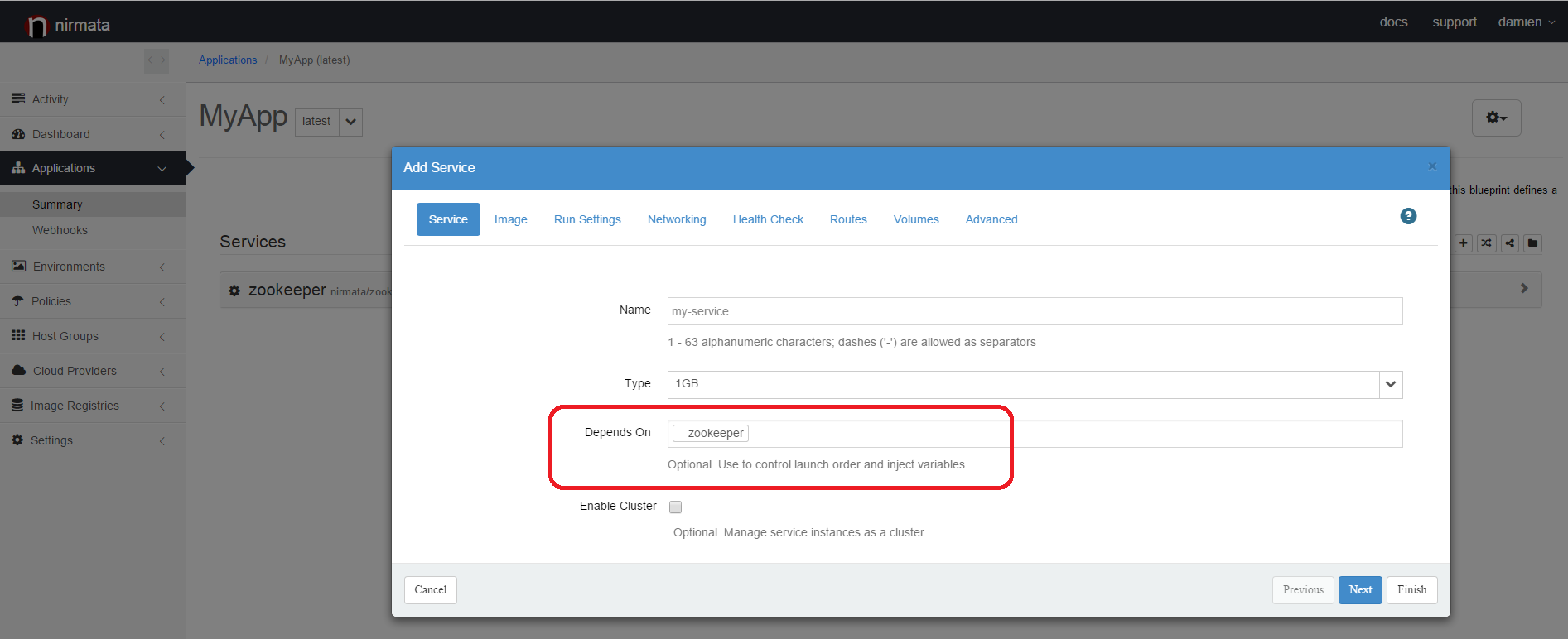
This will indicate to Nirmata orchestration that Zookeeper must be started first and then your services. An environment variable called NIRMATA_CLUSTER_INFO_zookeeper will be injected in all the containers running your services. The format of this environment variable is JSON. Here is an example for a 3 nodes Zookeeper cluster:
[
{
<span style="line-height: 1.5;"> "nodeId": 1,
</span><span style="line-height: 1.5;"> "ipAddress": "173.37.41.20",
</span> "ports": [
{ "portType": "TCP", "containerPort": 2181, "hostPort": 2181, "portName": "ZOOKEEPER_PORT" },
<span style="line-height: 1.5;"> { "portType": "TCP", "containerPort": 2888, "hostPort": 2888, "portName": "PEER_CONNECT" },
</span> { "portType": "TCP", "containerPort": 3888, "hostPort": 3888, "portName": "LEADER_ELECTION" }
],
},
{
"nodeId": 2,
"ipAddress": "173.39.228.30",
"ports": [
{ "portType": "TCP", "containerPort": 2181, "hostPort": 2181, "portName": "ZOOKEEPER_PORT" },
{ "portType": "TCP", "containerPort": 2888, "hostPort": 2888, "portName": "PEER_CONNECT" },
{ "portType": "TCP", "containerPort": 3888, "hostPort": 3888, "portName": "LEADER_ELECTION" }
],
},
{
"nodeId": 3,
"ipAddress": "173.37.41.200",
"ports": [
{ "portType": "TCP", "containerPort": 2181, "hostPort": 2181, "portName": "ZOOKEEPER_PORT" },
{ "portType": "TCP", "containerPort": 2888, "hostPort": 2888, "portName": "PEER_CONNECT" },
{ "portType": "TCP", "containerPort": 3888, "hostPort": 3888, "portName": "LEADER_ELECTION" }
],
}
]
Your application can parse this environment variable in order to build the Zookeeper connect string.
The Zookeeper Application Blueprint
Nirmata's Application Blueprints allow modeling for complex applications and service orchestration policies. In this section, we are going to take a look at the details of the Zookeeper blueprint. You really don't have to understand these details if you simply want to deploy a Zookeeper cluster . However, it is recommended to understand the details of the blueprint if you want to scale-up or down a cluster, or run a cluster on a limited number of hosts or even run multiple clusters on the same set of hosts.
The first section defines the most basic parameters required to create a Zookeeper container:
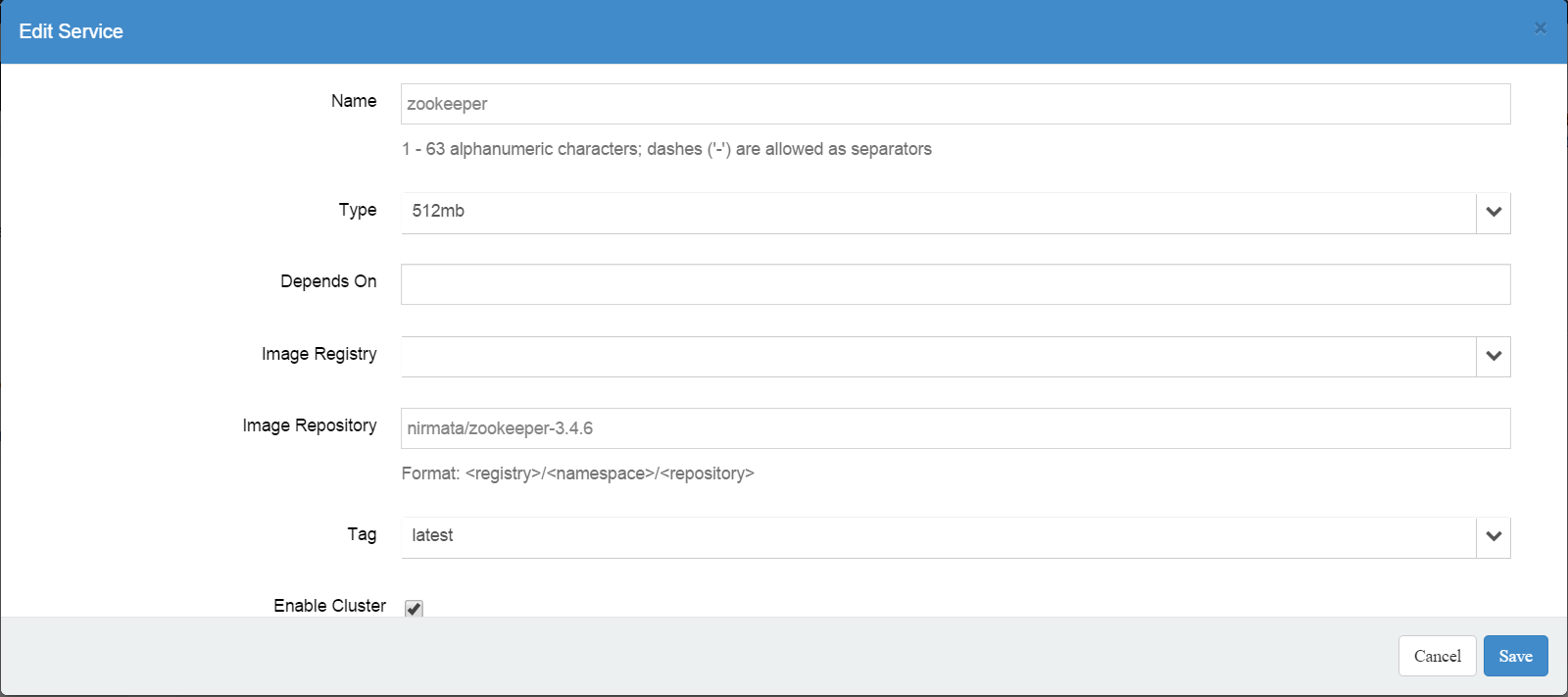
The field "Type" indicates the type of container to use to deploy the Zookeeper node. The container type specifies the amount of memory reserved for this container. You can change the container type if you want to use more memory for your Zookeeper nodes.
The Image Repository field specifies the Docker Image Repository to use in order to create the container. We have posted the Zookeeper Image Repository on DockerHub. Keep in mind that this image is only intended to be deployed using Nirmata solution. It won't work outside of Nirmata. We have also posted on GitHub all the files used to build that Image Repository: https://github.com/NirmataOSS/zookeeper-3.4.6
The last parameter in this section of the blueprint is the Cluster flag. It is used to indicate to the Nirmata orchestration that a special type of orchestration is required: The placement of all the nodes is computed up-front so specific environment variables can be injected in dependent client services, restart and recovery of the nodes always happen on the same nodes, etc.
The Next section of the blueprint is the networking section.
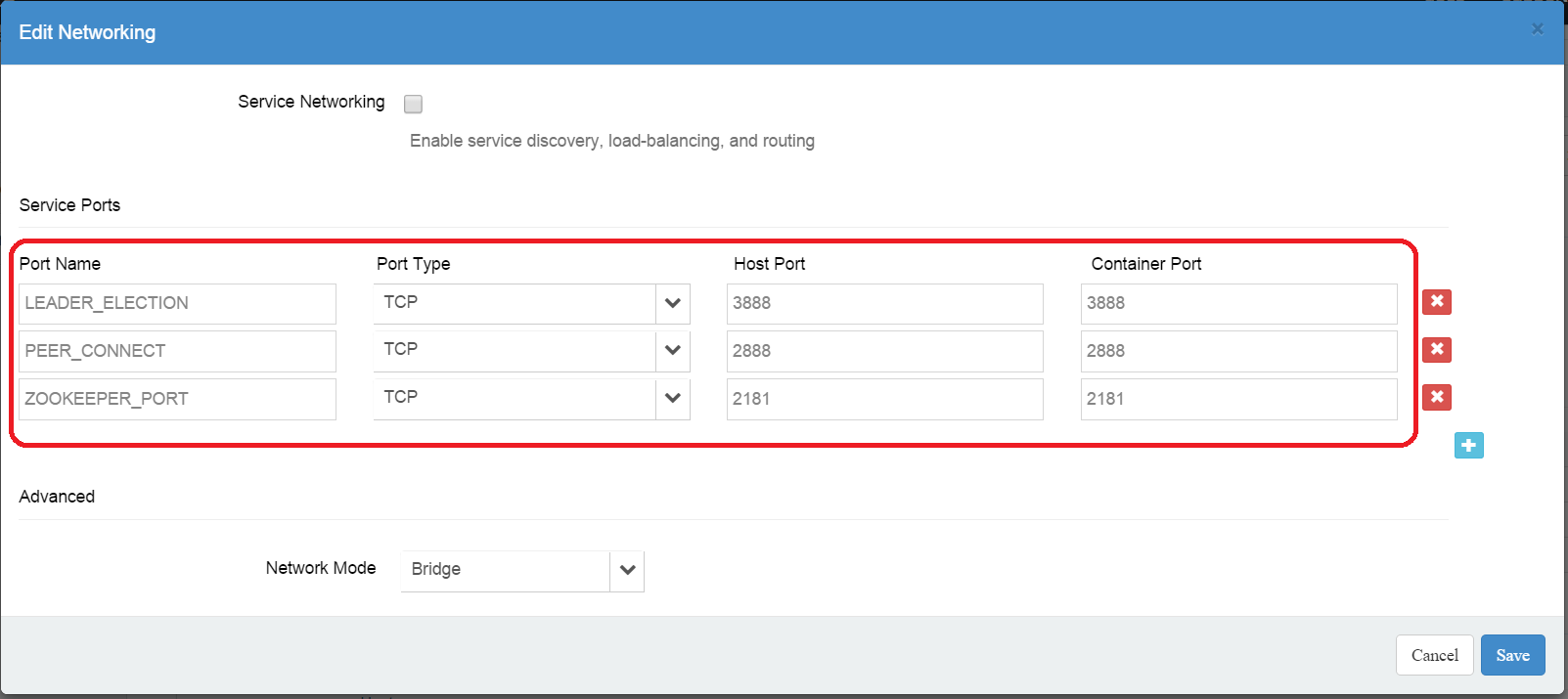
In this section we have specified the 3 ports exposed by each Zookeeper node:
- The client port: This port is used by client applications to connected to Zookeeper
- The peer connect port: This port is used by the Zookeeper nodes to perform the data replication
- The leader election port: This port is used to run the leader election algorithm
You should not change the name of these ports as there are used in the Zookeeper startup script. However, you can change the host port if you which to use different values. You can also let Nirmata allocate dynamically the host port by setting its value to 0. This option allows you to run a multi node cluster using a number of hosts smaller than the size of the cluster. Letting Nirmata allocate the port values dynamically prevents from having port conflicts when more than one node run on a single host. You can run an entire cluster of 3 nodes, 5 nodes or more on a single host. You can also run multiple clusters on a single host if you want to .
The next section of the blueprint is the Volumes section:
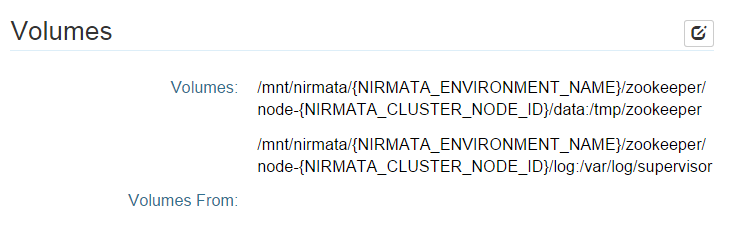
This section specifies how the Zookeeper data directory and the log directory are mounted on the host. The interesting aspect of this definition is that we have used two Nirmata environment variables that are instantiated at runtime when the containers are created:
NIRMATA_CLUSTER_NODE_ID:
This variable is replaced at runtime by an integer ranging from 1 to N where N is the size of your cluster. This particular environment variable allows us to run multiple nodes of the same cluster on the same host if required. Each node will have its own directory for data and logs.
NIRMATA_ENVIRONMENT_NAME
This variable is replaced at runtime by the name you gave to your environment. This is what allow us to run multiple Zookeeper clusters on the same host if required.
The last section of the blueprint we want to explore is the Run Settings section and more specifically the Environment Variables part:
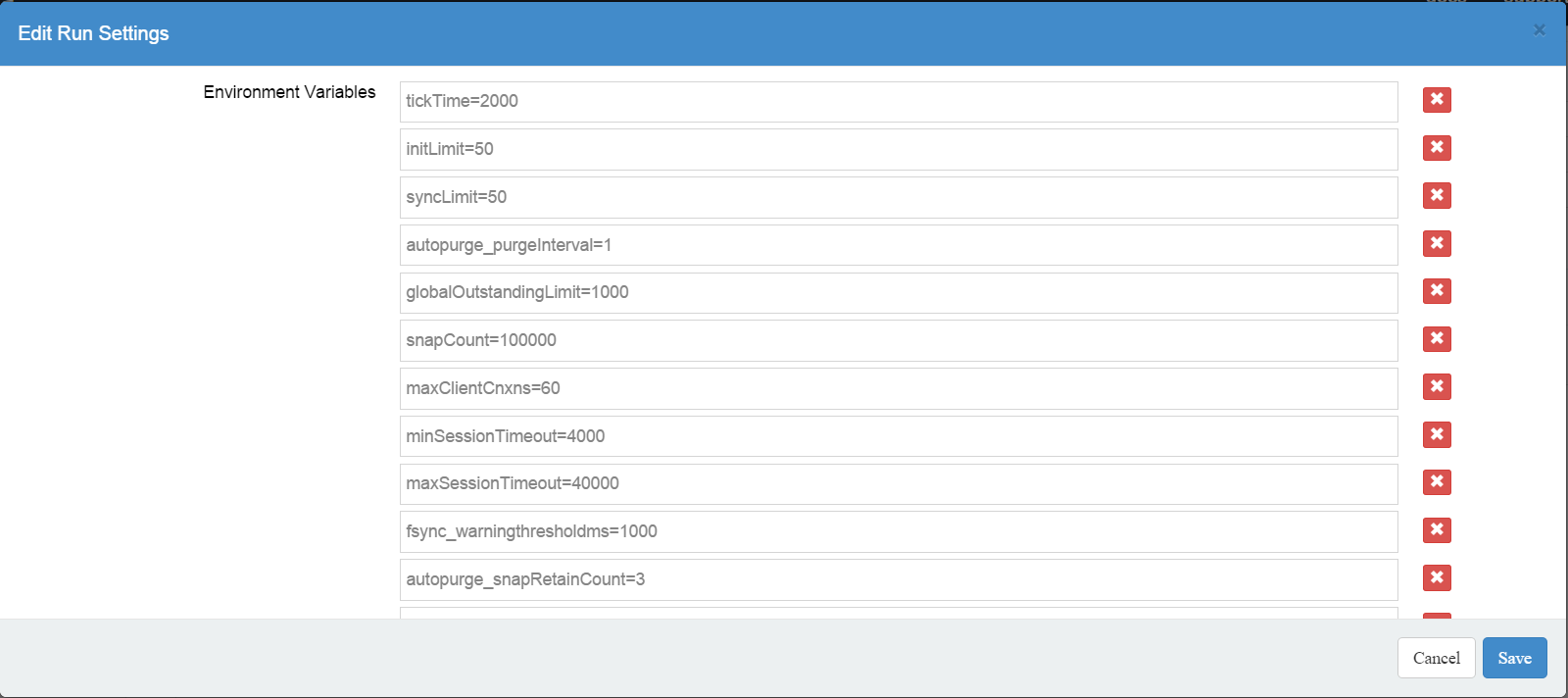
We have defined here some of the the most important Zookeeper configuration parameters. The values specified here are injected at runtime into each container in the form of environment variables. The Zookeeper startup script reads these environment variables and it generates the Zookeeper configuration file (zoo.cfg) at runtime. You can modify the values of these parameters but you should not delete or add new parameters. If you think that we have missed an important parameter, let us know. We can add this quickly.
What's Next?
We have seen that by "containerizing" a cluster like Zookeeper and by using an advanced orchestration solution, we can transform what used to be long and complex operations into a fast and trivial exercise. We would love to get your feedback and work with you on any aspect that would need improvements.
In the next few weeks, we will publish similar blueprints for Kafka, MongoDB and Elasticsearch. Let us know if there are other cluster services that you would like us to add to the list or prioritize. You can contact us at customer-success@nirmata.
Damien Toledo
Founder and VP of Engineering
Nirmata
Follow us @NirmataCloud